
Ship better software. Own your stack.
Open source tools, premium products, and a developer community built around production-grade solutions without vendor lock-in.
The stack we use. The tools we build.
Trusted by thousands of developers
We build tools for self-hosting, deployment, and development -- and a community around using them well.
Open source repositories
Docker images, server automation, developer tools, and more.
Stars on GitHub
Developers use and recommend our work.
Downloads per month
Running in production across teams of every size.
Subscribers
Updates on new tools, releases, and what we're learning. No spam.
 Join our Discord
Join our Discord Our Products
What we've built
Premium products and open source tools used by thousands of developers.

Sell self-hosted software in minutes. Push your Docker image, connect Stripe, and let your customers install with a single command.
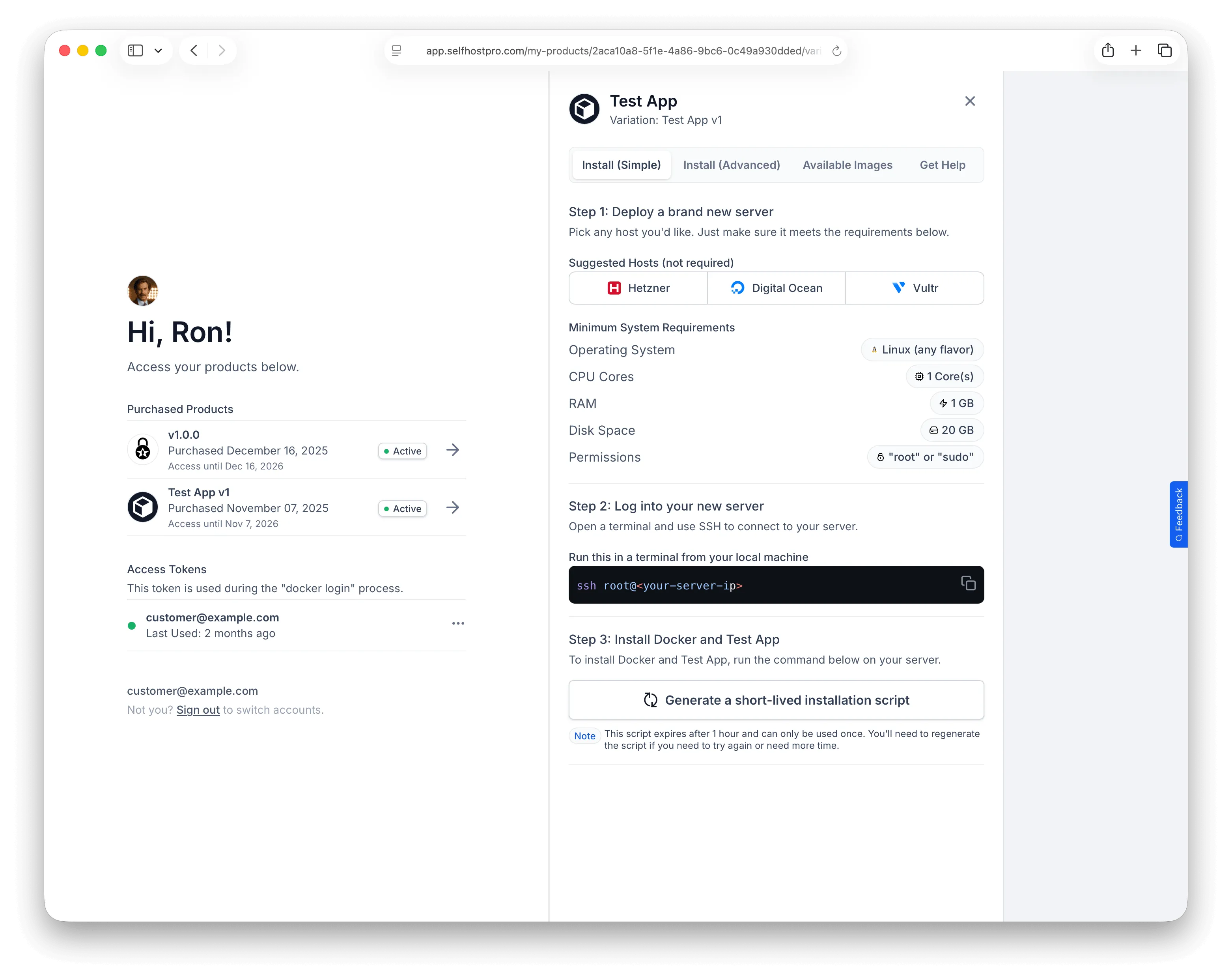

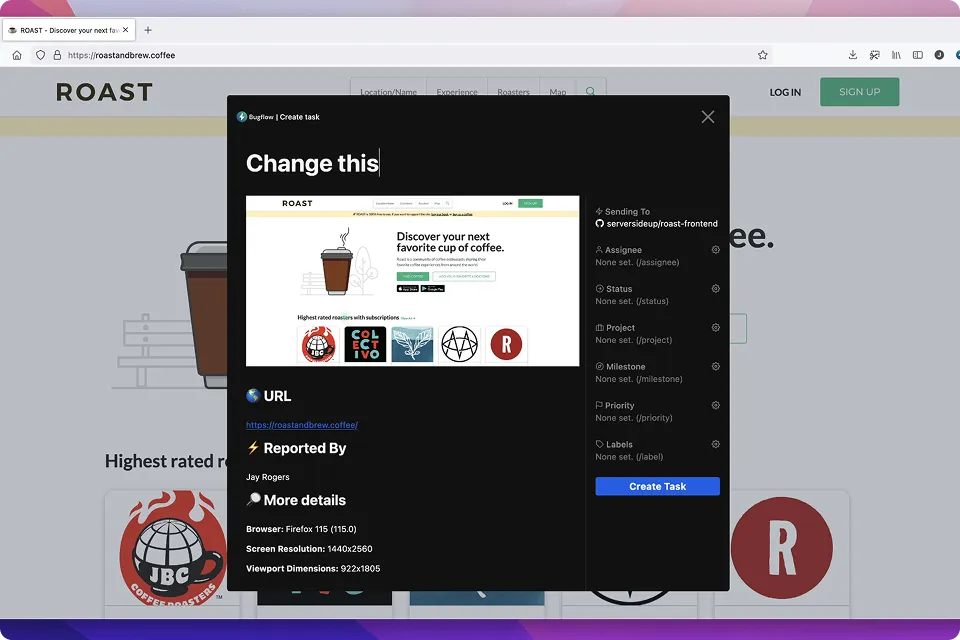
Improve your product through visual product feedback. Bugflow captures feedback from customers and internal testers and puts them into your existing project management flow.

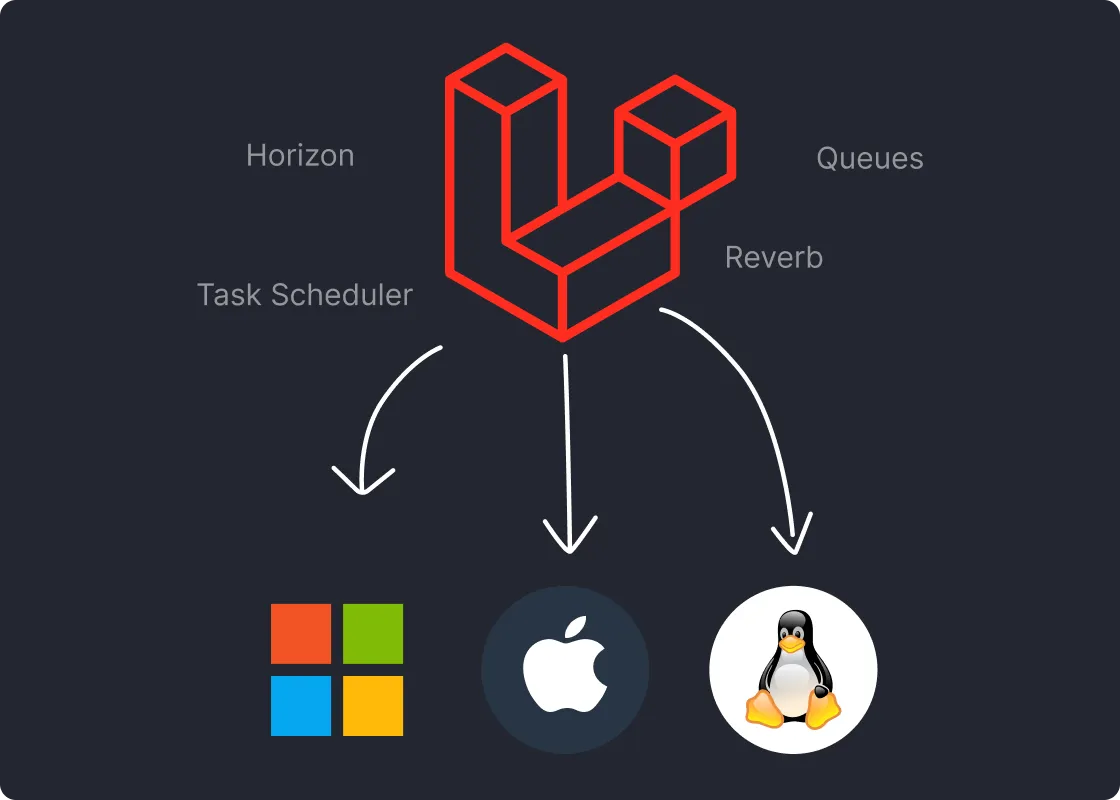
Based on a collection of our open source projects, Spin Pro enables Laravel Pros to ship software with the power of a PaaS to any VPS host of their choice. Available as PAY ONCE infrastructure.
Building Browser Extensions
Learn how to efficiently build browser extensions for every major browser from the same codebase. Source code examples for every major JavaScript framework is included.

Ultimate Guide To Building APIs & SPAs
Learn how you can use a Laravel API with a Nuxt frontend. You'll then learn how you can take that same Nuxt code and compile it into iOS and Android apps using the same codebase with Capacitor. Includes source code, Figma templates, videos, and more.


Our open source PHP Docker images are production-ready and optimized for Laravel and WordPress. Configuration is a breeze with environment variables. Choose between FPM+NGINX, NGINX Unit, and more.
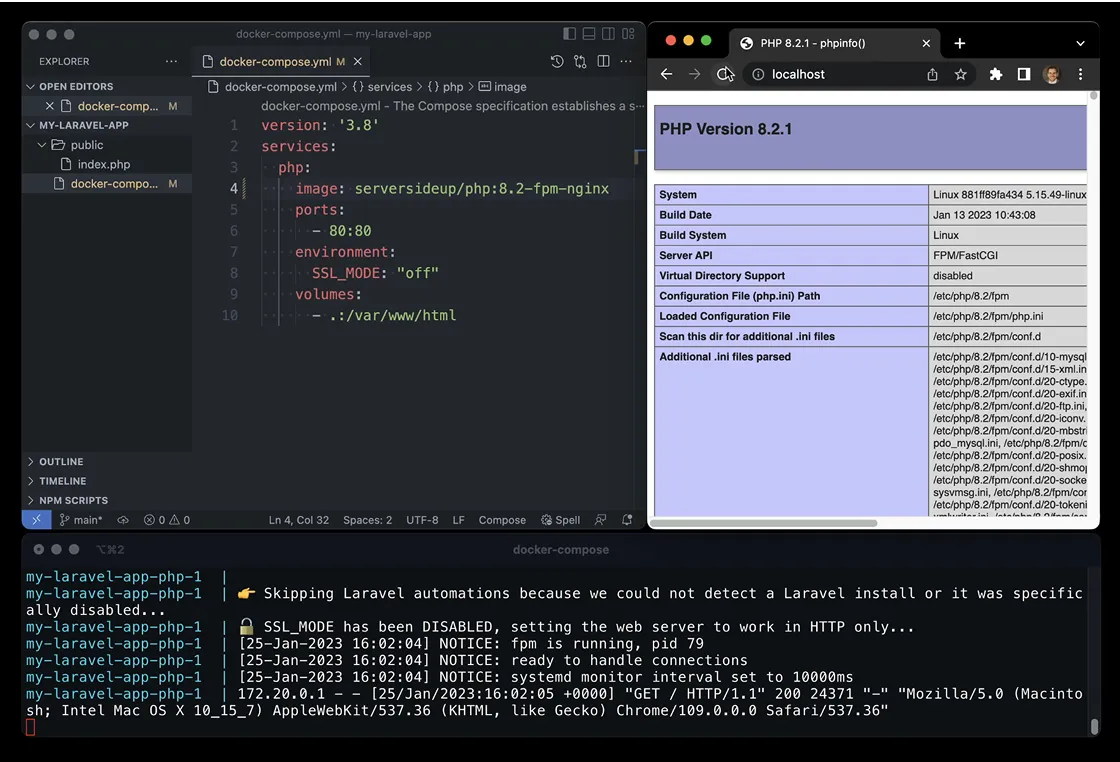

Get the power of running a PaaS on any VPS host of your choice. Run your application in a 100% replicated workflow on macOS, Windows, and Linux all using Docker.
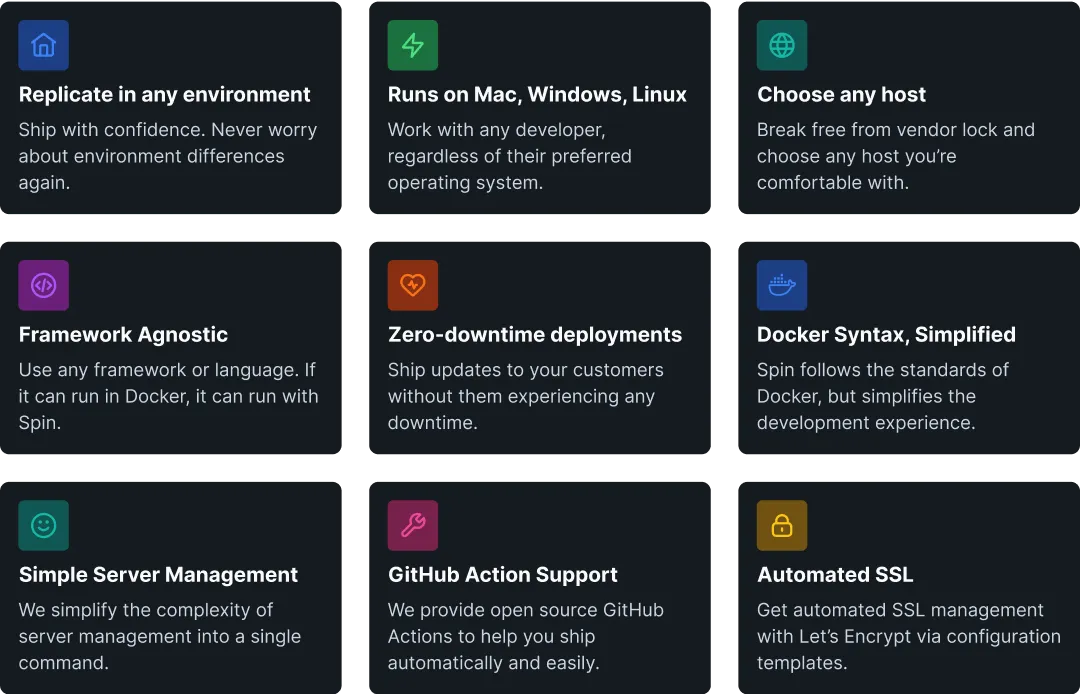

An open source alternative to Mint and YNAB. Track your expenses and never worry about your financial data being used by investors again.
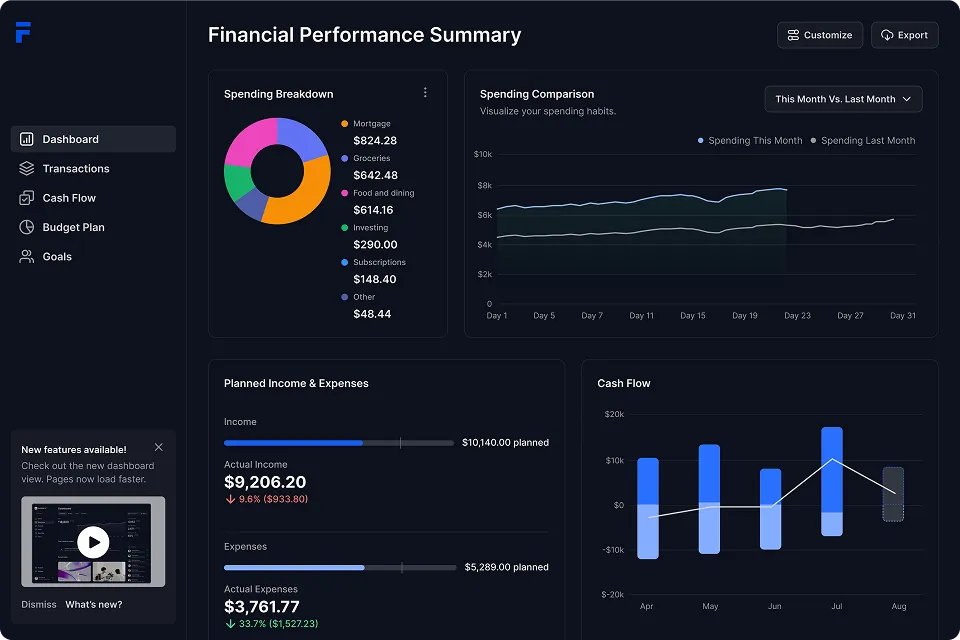

Gain full control of the web audio element in HTML5. Design your audio player to exactly match your vision. Use visualizers to take your audio to the next level.

Simplify the communication between your browser extension's components with a type-safe messaging library for Chrome, Firefox, and Edge.

Need help building your app?
Two senior engineers who've been building together since 2011. Full-stack expertise for a fraction of what a full-time hire costs.

Dan Pastori
Full-stack Engineer · 16+ years

Jay Rogers
UX Designer & DevOps Engineer · 20+ years
 Fixed monthly cost, no surprises Start in 48 hours, no recruitment Full-stack from design to deployment Production-grade code, not AI slop
Fixed monthly cost, no surprises Start in 48 hours, no recruitment Full-stack from design to deployment Production-grade code, not AI slop  Hire Us
Hire Us Latest posts
Our Blog
Latest releases, how-to articles, and more.

OAuth and Other Authentication Methods

Designing an Installation Script
Docker Compose Bind Mounts vs Named Volumes: When to Use Each
Join our community
We're a community of 3,000+ members help each other level up our development skills.
Platinum Sponsors

Active Discord Members
We help each other through the challenges and share our knowledge when we learn something cool.
Stars on GitHub
Our community is active and growing.
Newsletter Subscribers
We send periodic updates what we're learning and what new tools are available. No spam. No BS.
Sign up for our newsletter
Be the first to know about our latest releases and product updates.
We're a community empowering product builders with self-hosted tools and open source solutions.